24dec06
[title]
- include ‘tools for thought’
[story]
- covid days 2020 – intro to writing – basb – nuweiba 2021
- include conaw twitter thread
[problem] Information capture
- intro of the problem has to be painful
- quantify: include some numbers / stats
- info overload?
- fragmented knowledge
- siloed thinking
[solution] frictionless notes
- ‘quick capture’ approach
- audio transcripts
- conversations
- mobile app
- online articles on web
- books – kindle (tablet), hardcover, audio (audible), on computer (apple books, pdfs)
- attach my notebook photo from 2020 about multiple types of data
- chrome extension
- multiple use cases
- existing apps
- readwise
- read laters apps
[value]
[helpers]
- intro to ‘tools for thought’
- emphasis on basb as a practice
- i did a ‘quickstart’ 2 years ago, my sister told me i don’t get it
- explanation has to be easy to understand for beginners
- visuals from nuweiba, initial days of basb
- intro to KM, include examples
- KM pipeline visual (24nov23)
- capture–manage–recall
- capture–connect–organize–search
- consume–capture–organize–create–share
- c-o-d-e
- talk about the creator economy?
- 24Oct28 | How to use note-taking for time travel?
- 23Jun19 | I have tried every journal app that exists
- Interlude
- 23May15 | What I’m working on & why I became interested in time travel
- [Random notes] HSS Pitch Draft II
- 24Feb03 | Tools for thought
- 24Mar28 | Time as a computing platform
- 23Aug13 | The Three Search Problems
- 24May11 | 1 year of Hyperspaces
- 23Apr15 | Time travel by means of searching anything you read, write or say

24dec10
→ gathering helping resources
→ idea outline
24dec11
→ essay outline
→ scoping ‘the problem’
24dec12
→ first draft (text only)
→ ‘the problem’ articulated
→ feedback on draft I
24dec13
→ finalize the hyperspaces section
→ include visuals (designs)
→ include photos (relevant to story)
→ feedback on draft II
24dec14
→ include cta section
→ feedback on draft III
24dec15
→ proofread, publish
- covid days (intro)
diving into tools for thoughtattending basb, learning the concepts, talking with people- suffering from complexity
- photo: digital information page from my notebook
- data formats block (turn to usable design?)
- very big problem
- focus on information overload (multiple data sources, multiple formats, fragmented context) because we’ll talk about other problems later
- added complexity, used lots of apps, did lots of workarounds
- visual – siloed artificial apps vs biological brain
- include numbers
- very simple solution
- explain events: life experiences from things that happen in your life
- explain it philosophically –
- Navigating a temporal space creates the capacity needed to see afresh problems from your day, your work, and your life. Ideas collide and connect in ways they never would have on a static linear plane.
- explain ‘daily notes’? why is it so powerful
- reflect docs: daily journal
- check craft blog for a similar entry
How to capture knowledge from the internet?
Part I of the ‘How to build a second brain’ series – and 3 principles of note-taking
During the height of the covid pandemic lockdown, there was no way out of the screen. If you are an average computer user, your screen time jumped from 5 to 13 hours per day. This initiated a consumption frenzy, where we were consuming far more information than we knew what to do with.
Then the lockdown ended, but the consumption frenzy didn’t.
Since 2021, it actually skyrocketed. Fight over your attention had just started.
Youtube shorts hit 70B daily views, up 6x from 2021.
Instagram reels doubled year-over-year, up 8x from 2021
Podcasts grew from 2M to 5M shows per year, up 2.5x from 2021.
We could keep going, but I’m not here to talk about implications on culture. Instead, I want to discuss how to capture and make sense of all this information. Because if we don’t then there’s no point of consuming any of it.
Since 2021, I have been struggling to answer the question “How to process and retain everything I learn across time.” Answer to this took me through several phases; each becoming progressively simpler than the one before. From complicated, to complex, to simple.
In this post I’m willing to discuss the simplest practice I could use to:
- Gain maximal benefit of things I spend time on – That is things I create, work on, or interact with, by saving as much of them for my future self
- Spend minimal time doing it – I don't want to spend hours capturing information, as new information continues to accumulate anyway, so I’d rather capture them as they happen
This means that for effective information capture, there only has to be two principals:
- Capture has to be contextual
- Capture has to be frictionless
I’ll explain what do I mean by that in a second. But first, here’s a quick look of some types of information I create*, and where they normally belong:
caption: *things we create (i.e book highlights, podcast notes, web bookmarks) often exist in places different from the medium of consumption of things that led to them (i.e kindle, apple podcasts, youtube videos), which is almost another problem – Now the question we’re trying to answer here is not how to facilitate consumption but rather how to facilitate recall – That is by effectively storing things we work on, or spend time interacting with, in any capacity
Here, I described 22 different places to store digital information. And that is information we use daily. So on a given day, the standard practice is to switch between ~22 places on our computer.
<visual of fragmented knowledge>
The human brain can only process a limited number of scopes at a time. So when you're dealing with 22 different apps, even if you're not actively using them all at once, the cognitive load of remembering what's where becomes a disaster. This wouldn’t be a problem if this precious cognitive load is infinite, but it’s not. This problem is even bigger for people whose main capital at work is information; knowledge workers.
It’s estimated that roughly a third of the workweek is wasted on knowledge management. Knowledge workers spend up to 2.5 hours per day searching for information across different apps and platforms. This is not work, that is 2.5 hours per day reconstructing the context needed to start working.
This search takes all this time because it conflicts with how the human brain naturally works. Our brains don’t save information in silos – they don't store individual thoughts, documents, or ideas in isolation. Strangely enough, the brain saves connections between all of them. So when we remember (retrieve) things at future points of time, we actually retrieve connections between things.
Unfortunately, our current capture practices do not account for any of this. Also, practices discussed in most knowledge management courses are sooo complex. I remember that one time I took an entire day to lay out a full-blown capture workflow of every data format I was using at the time. The result was this terrible image below.

Capture has to be contextual
In order to come up with effective ways to save information, we first have to understand how the brain saves them. After all, software should only serve as an extension of the mind, rather than forcing the mind to adapt to it.
Let's assume you're working on a project where you have meeting notes in Notion, task boards in Linear, relevant threads on Slack, and some related files in Google Drive. Now every time you revisit the project, you'll spend significant time just trying to piece together all this information.
During this time, your brain is going from a state that looks like this:
<visual>
To a state that looks like this:
<visual>
If we want to bring this time to almost zero, the answer is definitely not to stop using the various tools, but rather facilitate context reconstruction across them. To do this, it’s important to understand that brains don’t remember information, but rather ‘Events’.
An event (life experience) is the minimum piece of context a brain is able to recall. Which means not just a piece of information, but a set of pieces that come together—relevant or not.
Examples:
- Locations: Lots of our memories are bound by where we are. So just by remembering/revisiting a location, you could remember lots of other things like activities, projects, the weather, etc.
- Music: Listening to music you used to listen to when you were young doesn’t just remind you of the music, but also triggers memories of events, people, and places from that time.
Now since our brains naturally store information as interconnected networks, not as isolated pieces in separate containers, it’s clear that this quick context reconstruction has to be a main function of whatever tool we use for storing information.
Capture has to be frictionless
Now before jumping to what software to use, let’s assume the above is already achieved, we’d still have one more problem.
In an ideal world, if we’d have an infinite canvas of all thoughts we ever had, with the perfect context, and the perfect log of everything, we will never lose a thing, so we’d have no problem. But since this is not practical, and since we wouldn’t be able to keep track of everything, there still exists the problem of ‘friction’.
Example:
If you’ve ever used apple journal, this is what you’d find.
<screenshot>
<good example>
It collects photos, location data, and activities from other places and presents them for you if you want to write about that life ‘event’. But if you don’t, it’s still not a problem because now you have a record of it (automated), which helps future recall either way.
Thus, it’s not only sufficient to have fuller context, but also this context capture has to be automated as much as possible. So if there’s a way where all as much as possible of this information is auto-recorded, we might have a shot at having these detailed records of everything.
~The solution
Now the solution becomes not just to ‘capture maximum context’ but ‘capture maximum context with minimal friction.’
<rephrase to layman>
Earlier, we discussed how knowledge management is just an effort to reduce the number of places we look at. Building on that concept and the two key principles we just covered, the most important types of tools that can help us achieve this are:
- A screentime tracker
- A highlight capturer
I believe these two are the most essential tools for capture because they complement each other: a screen time tracker automatically logs everything we interact with, while a highlight capturer records the more in-depth stuff.
💡 visual: a page (surrounded by a screentime item red rectangle) + a highlight from the page (surrounded by a highlight red rectangle)
Screentime tracker
Examples: Timing, RescueTime
Screentime trackers provide the richest context of any capture tool. It does two things:
- Shows how much time we spent doing something on screen
- Records deep links and activity paths across different apps
This second function is what allows us to have the full history of everything without friction. I can look into details by hovering over a time chunk, which shows me actual paths and links I spent time on, along with the full context of what came before and after.
To visualize this concept, this is a sample day captured in a screentime tracker – notice how I’m able to access original links and resources I spent time on:
In the above video, every digital item we interact with already has ‘time’ associated with. In this regard, a digital timeline enables the automatic capture of these items without having to stop and bookmark any of them.
In other words, the original format of the information doesn't matter—whether it's a Notion doc, Slack message, Python script, Linear board, or PDF book—since they're all captured and organized by a universal format: timestamps.
This is a good step towards breaking isolated silos, and building this ‘infinite canvas’.
It effectively captures webpages and resources as we interact with them.
What about capturing specific text or highlights from books and essays?
Highlight capturer
Highlight capturers enable saving text excerpts from any place on the internet into a library of your own.


While a screentime tracker captures the link of the essay I’m reading, a highlight capturer enables saving specific pieces of text from the essay. This can be done for books, tweets, academic pdfs, articles, etc.
Although there are lots of concepts and tools in this space, the above toolkit is what I believe is the only stack needed for smooth capture. The next step after capture would be to manage and organize things we captured, which we’ll cover in detail in the next part of this series “How to build a second brain”.
<subscribe button>
I’m currently working on a tool called Hyperspaces, whose main function is to connect and search captured items from both screen and highlight trackers.
Reason for this is, although I have been using the above toolkit for years, it still misses the following:
- Ability to add rich notes to captured items
- Ability to search captured items
- Ability to merge captured items
Hyperspaces is a note-taking tool for thinking and research. It enables you to search, browse, and add rich notes on top of your entire digital history in one place.
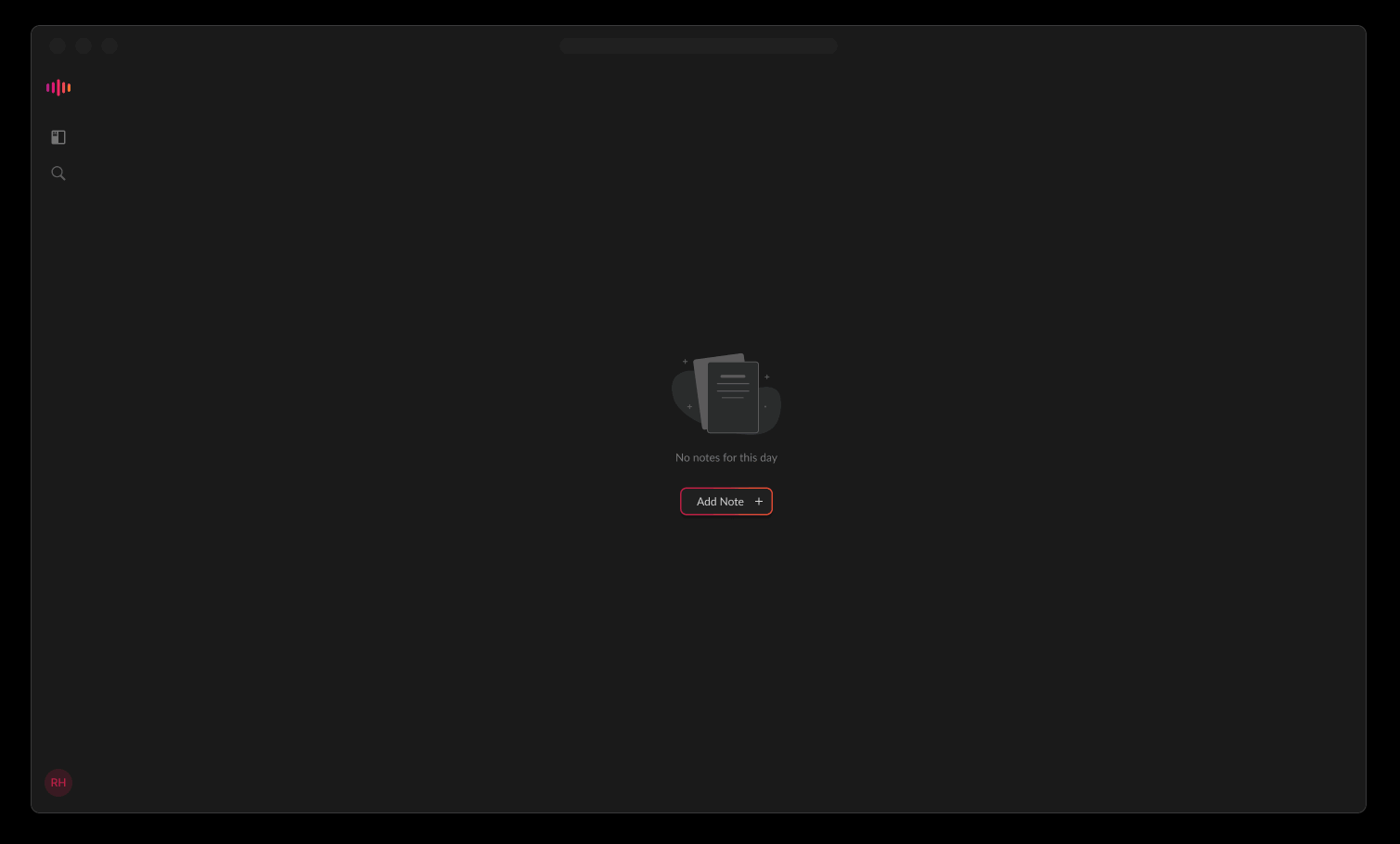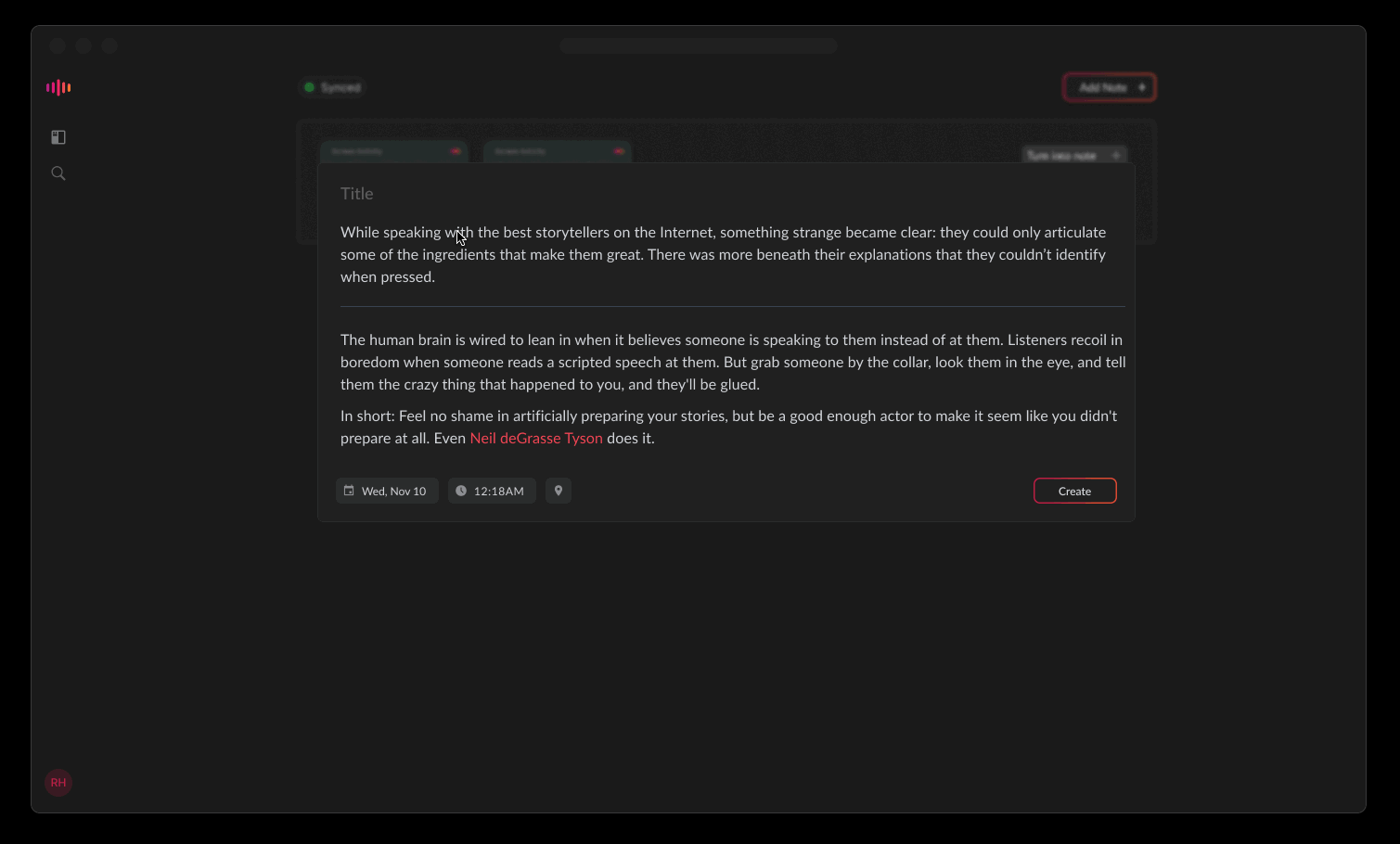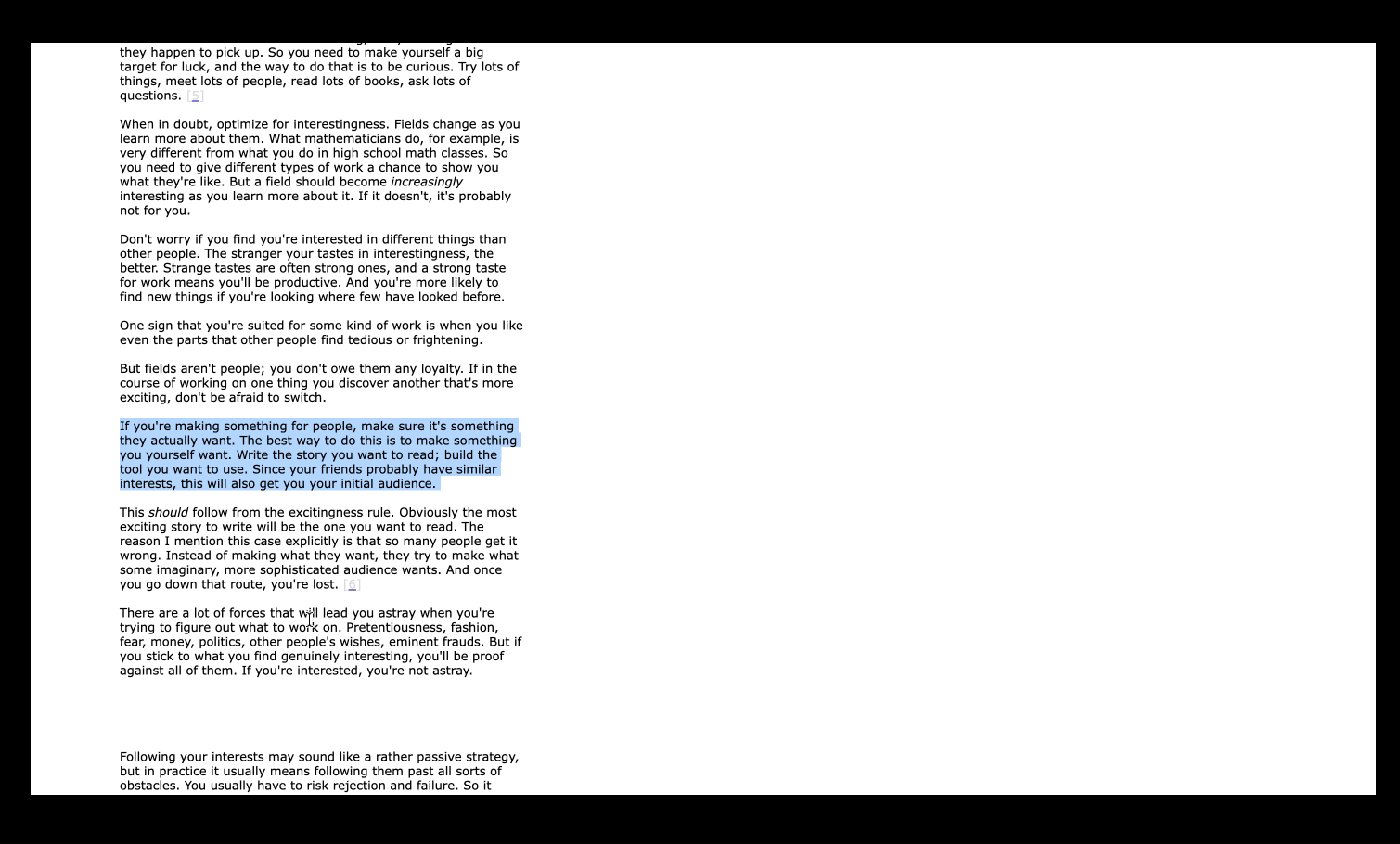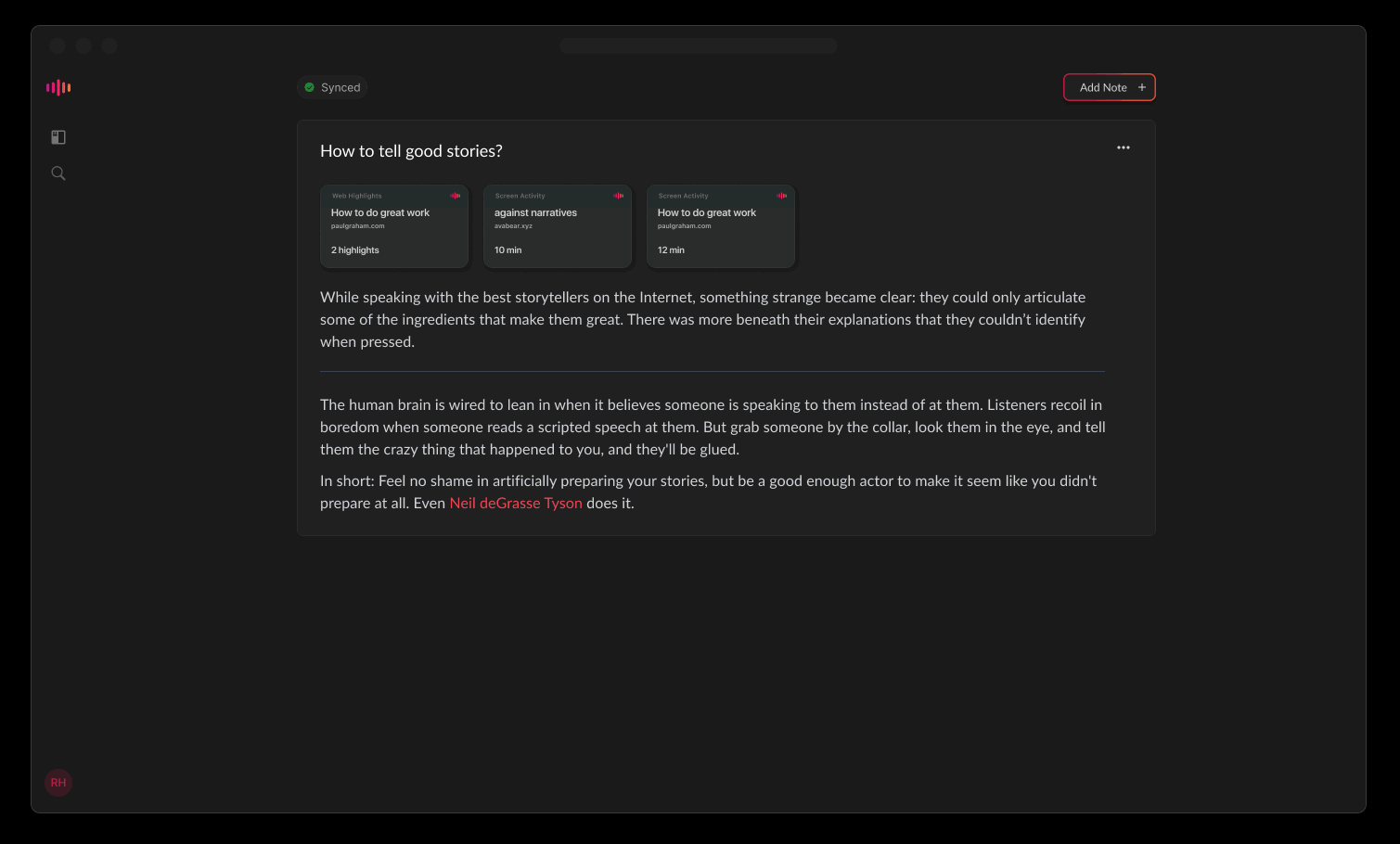
<turn to video>
Here, a note can represent an event (a set of pieces of information) rather than one isolated piece. So the unit of knowledge inside Hyperspaces is the same as that of the brain. That is the minimum piece of context the real brain is able to recall –which is not an orphan text, a photo, a tag, or a card– but an event; a chunk of ‘life experience.’
We briefly opened Beta access in October but now it’s back in closed Beta, where me and my small team are working with a tight group of users to polish core features and gather feedback.
If this is interesting to you and you’d want to join, feel free to fill the Beta Program form and I’ll reach out to you:
Or if you are interested to discuss the tool or nerd out about knowledge management in general, I would be happy to have a friendly chat. Book my calendar directly from here:
<Calendar>
Let me know in the comments what is your current capture toolkit? What worked best for you?
<Leave Comment>
For example, you could search for a specific topic and see all your related browser history, highlights from articles and books, notes, and more - all organized chronologically on a timeline. This helps reconstruct the full context of your work and learning over time.
If you're interested in trying out Hyperspaces or learning more, feel free to sign up for early access on our website.
events & how the brain works
- Time as a computing platform
- 24Apr11 | Events as fundamental units of the timeline
- 24Oct28 | How to use note-taking for time travel?
daily notes / the timeline
- <the above → the timeline>
- ‘daily notes’ as a concept
- once there, every valuable idea or piece of information finds its way through time
draft
on AI:
- ultimately AI will be able to mix knowledge with data into a second brain
- we’d be able to complement our daily knowledge with real-time data
- this is highly critical, i can’t express it enough
- as we speak, lots of new tools are being built such that AI can crunch enormous spreadsheets and turn them into english – so the long hours we used to spend to extract insights from numbers, i.e turn structured data into knowledge, will be shortly done by AI
draft
- ideas / perspectives
- writing is thinking
- notes are a medium for time travel
- knowledge is continuous
- browser agnostic → “if we’re capturing links we’re spending most time on, we don’t have to care about which browser we’re using – chrome, arc, or whatever”
- screentime <> the ‘3 spaces’ → search!
- include screenshots of timeline events (5-6 during the day) with 1-item events, suggesting screen activity items, and a few others with notes, and how these items stick on top of them magically